

Next: 3.2 Private X Resources
Up: 3 Reinventing X11
Previous: 3 Reinventing X11
D11's most important optimization is making the packing and unpacking
of X11 protocol and its transport optional in the local case. Standard
implementations of Xlib and the X server work by writing and reading X11
protocol over a reliable byte-stream connection (usually TCP or Unix
domain sockets). Excepting local optimizations to these underlying
transport mechanisms [10],
the local and remote case use essentially the same mechanism.
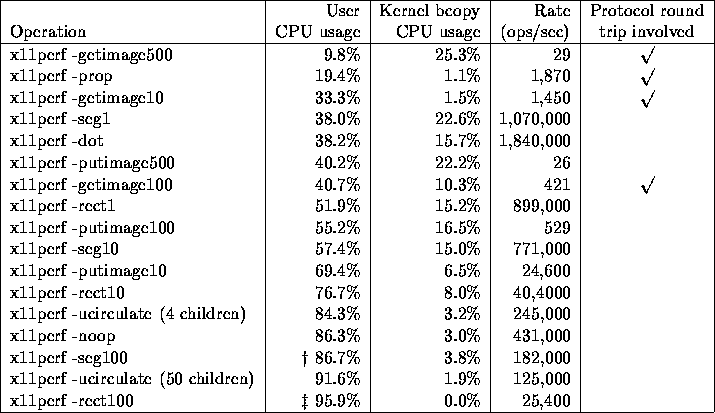
Table 1: Indications of processor utilization bottlenecks
for assorted X operations. These results are generated by kernel
profiling of an R4400 150 Mhz SGI Indy running IRIX 5.3. User CPU usage
includes both client and X server CPU usage jointly. During the measurements,
the CPU was never idle. Notes:
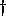 includes 42.3% of time
actually spent in kernel's stalling graphics FIFO full interrupt handler.
includes 42.3% of time
actually spent in kernel's stalling graphics FIFO full interrupt handler.
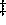 likewise includes 84.0% of time
spent in FIFO full interrupt handler.
likewise includes 84.0% of time
spent in FIFO full interrupt handler.
Consider the work that goes into this packing, transport, and unpacking
process. The individual steps underlying a typical Xlib and X server
interaction look like:
- The client program makes an Xlib call.
- Xlib packages up the call arguments into X11 protocol in an
internal buffer.
Steps 1 and 2 repeat until Xlib determines the protocol buffers
should be flushed. This happens because a reply needs to be
received, an explicit XFlush call has been made, the buffer
is full, or Xlib
is asked to detect incoming events or errors. Buffering X11 protocol
is an important Xlib optimization since it increases the
size of protocol transfers for better transport throughput.
- When a flush is required, Xlib writes the protocol buffer
to the X connection socket, transferring the data through the
operating system's transport code.
- The X server has an event dispatch loop that blocks checking
for input on client sockets using the select system call.
- select unblocks and reports pending input from a client
that has written to its X connection socket.
- The protocol request is read by the X server, the type of the request
is decoded, and the corresponding protocol
dispatch routine is called.
- The dispatch routine unpacks the protocol request and
performs the request.
If the request returns a reply, the sequence continues.
- Xlib normally blocks waiting for every reply to be returned.
- The X server encodes a protocol reply.
- The X server writes the reply to the receiving client's
X connection socket.
- The client unblocks to read the reply.
- The reply is decoded.
There are a number of inefficiencies in the local case of the
protocol execution sequence above.
Table 1 shows that a
number of important X operations can spend from 25% to 90% of their
time within the operating system kernel.
Clearly, operating system overhead can have a substantial impact
on X performance.
There are three types of operating system overhead that are
reduced by D11:
- Protocol packing and unpacking.
-
The protocol packing and unpacking in Steps 2, 7, 9, and 12 are done
strictly according to the X11 protocol encoding. Unfortunately,
the protocol encoding is designed for reasonable compactness so
16-bit and 8-bit quantities must be handled and packed at varying
alignments that are often handled relatively inefficiently by
RISC processor designs.
Using protected procedure calls, a process directly passes
D11 API routine parameters to the window system, skipping the
inefficient packing and unpacking of protocol.
- Transport.
-
Moving X protocol from one process to another in Steps 3, 6, 10, and 11
requires reading and
writing protocol by the X server and its clients. Protected procedure
calls and an active context augmented address space allow data to
be passed to and from the D11 window system kernel without any
reading and writing of protocol buffers.
The kernel bcopy CPU usage percentages in Table 1
provide a lower bound to the transport overhead of X protocol transport.
The bcopy overhead is over 20% for some important X operations.
The bcopy overhead counts only the raw data copying overhead and
not the socket implementation and select overhead.
- Context switching.
-
Because the client process generating X requests is not the same
process as the one executing X requests, there is context switching overhead
for the completion of every X request. Fortunately, protocol buffering allows
this cost to be amortized across multiple requests, but the overhead
of context switching still exists. For X requests that generate a reply
forcing a ``round trip,'' the kernel overhead due largely to context
switching is quite high as Table 1 shows
(up to 80% for the x11perf -prop test
that is mostly context switching overhead).
Beyond the cost of the actual
context switch, there is a cost due to cache competition between the
client and server processes [6].
Execution of a protected procedure call is in effect a context switch,
but is hopefully a lighter weight context switch than the typical Unix process switch between
contexts. Among the advantages of a protected procedure call over a
Unix context switch is that no trip through the Unix scheduler is necessary
and that most processor registers do not need to be saved.
As an example of how the transport-less, protocol-less D11 window
system improves performance, consider an XGetImage
call. In X11, such a call is expensive because it requires
a client/server round trip representing two heavyweight context switches,
three copies of the image (an image copy from the screen to an X server reply
buffer; a copy from the reply buffer to the kernel; and a copy from
the kernel to the client), and the overhead of protocol packing and unpacking.
In a local D11 program, the same XGetImage call is implemented with a
single protected procedure call (two lightweight context switches),
no protocol packing or unpacking, and a single copy directly from
the screen to the D11 protocol buffer (because the caller memory
space is directly available within the active context).
Next: 3.2 Private X Resources
Up: 3 Reinventing X11
Previous: 3 Reinventing X11
Mark Kilgard
Sun Jan 7 19:06:56 PST 1996